This tutorial described you step-by-step tutorial to install Apache Kafka on Ubuntu 20.04 LTS Linux system. You will also learn to create topics in Kafka and run producer and consumer nodes.
Prerequisites
You must have sudo privileged account access to the Ubuntu 20.04 Linux system.
Step 1 – Installing Java
Apache Kafka can be run on all platforms supported by Java. In order to set up Kafka on the Ubuntu system, you need to install java first. As we know, Oracle java is now commercially available, So we are using its open-source version OpenJDK. Execute the below command to install OpenJDK on your system from the official PPA’s. Verify the current active Java version.
Step 2 – Download Latest Apache Kafka
Download the Apache Kafka binary files from its official download website. You can also select any nearby mirror to download. Then extract the archive file
Step 3 – Creating Systemd Unit Files
Now, you need to create systemd unit files for the Zookeeper and Kafka services. Which will help you to start/stop the Kafka service in an easy way. First, create a systemd unit file for Zookeeper: And add the following content: Save the file and close it. Next, to create a systemd unit file for the Kafka service: Add the below content. Make sure to set the correct JAVA_HOME path as per the Java installed on your system. Save the file and close. Reload the systemd daemon to apply new changes.
Step 4 – Start Kafka and Zookeeper Service
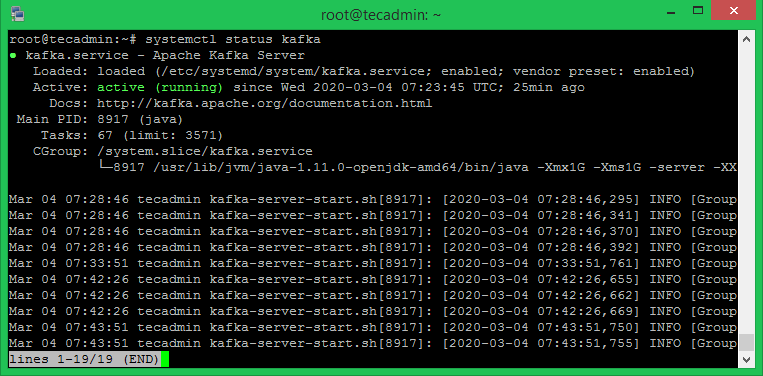
First, you need to start the ZooKeeper service and then start Kafka. Use the systemctl command to start a single-node ZooKeeper instance. Now start the Kafka server and view the running status:
All done. The Kafka installation has been successfully completed. The part of this tutorial will help you to work with the Kafka server.
Step 5 – Create a Topic in Kafka
Kafka provides multiple pre-built shell scripts to work on it. First, create a topic named “testTopic” with a single partition with a single replica: The replication factor describes how many copies of data will be created. As we are running with a single instance keep this value 1. Set the partition options as the number of brokers you want your data to be split between. As we are running with a single broker keep this value 1. You can create multiple topics by running the same command as above. After that, you can see the created topics on Kafka by the running below command: Alternatively, instead of manually creating topics you can also configure your brokers to auto-create topics when a non-existent topic is published to.
Step 6 – Send and Receive Messages in Kafka
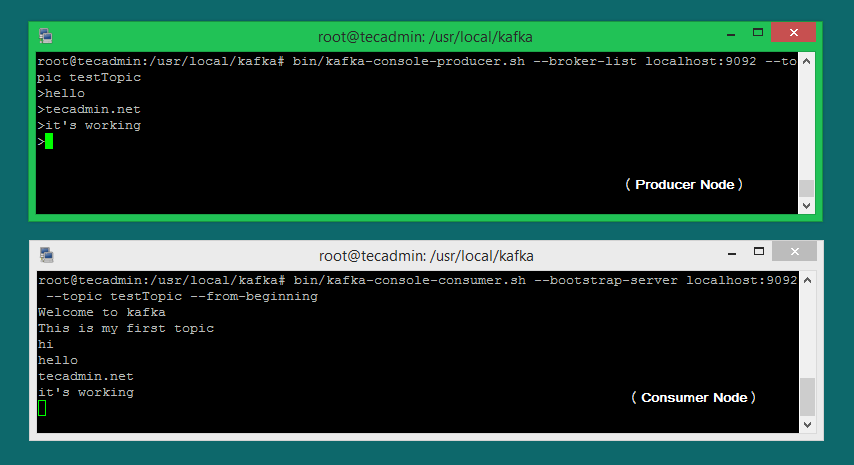
The “producer” is the process responsible for put data into our Kafka. The Kafka comes with a command-line client that will take input from a file or from standard input and send it out as messages to the Kafka cluster. The default Kafka sends each line as a separate message. Let’s run the producer and then type a few messages into the console to send to the server. You can exit this command or keep this terminal running for further testing. Now open a new terminal to the Kafka consumer process on the next step.
Step 7 – Using Kafka Consumer
Kafka also has a command-line consumer to read data from the Kafka cluster and display messages to standard output. Now, If you have still running Kafka producer (Step #6) in another terminal. Just type some text on that producer terminal. it will immediately be visible on the consumer terminal. See the below screenshot of the Kafka producer and consumer in working:
Conclusion
This tutorial helped you to install and configure the Apache Kafka service on an Ubuntu system. Additionally, you learned to create a new topic in the Kafka server and run a sample production and consumer process with Apache Kafka.